
One of the human behaviors that never ceases to amaze me is the gap between what people say they do and what they actually do. In management research, this is often referred to as espoused theory versus theory in use.
When it comes to digitalization and working with data, I see a similar pattern in many companies I work with. On the one hand, many consider data to be incredibly important and they don’t want anyone else to have access to it. As a consequence, companies are very restrictive about making their data available to suppliers and partners. When asked what they’re doing with the data, people often hide behind arguments concerning confidentiality and secrecy.
In practice, on the other hand, many companies aren’t using the vast amounts of data they collect at all. The only real use case is quality assurance diagnostics. Recording defects and the system context during which the defect occurred as a means to simplify defect removal is the main use of the data coming back from the field.
Very few of the companies I work with can, for example, answer questions concerning feature usage and the gap between product management predictions about the impact of new features and the actual outcome. This is in many ways surprising as everyone agrees that adding features that aren’t used is a significant source of both wasted effort and increased system complexity that reduces productivity when adding or changing other functionality.
We’ve developed a model capturing four dimensions of evolution when going through a digital transformation. These include the business model, product upgrade and AI. Here, we focus on the data exploitation dimension.
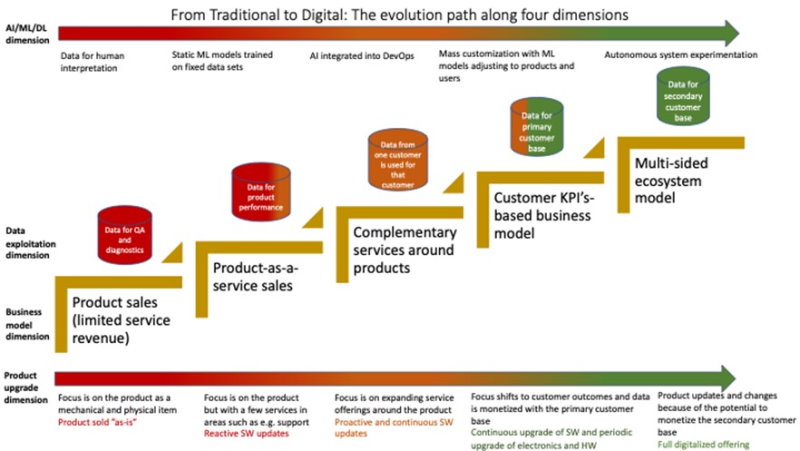
The first step is using data for quality assurance diagnostics, which is the state of many companies. The second step is concerned with product performance. Here, we collect data on feature usage and in general seek to align our R&D efforts with the quantitative outcomes we’re looking to achieve for our customers.
The third step is using the data we collect from systems at one customer for that particular customer. The idea is that the data we collect and analyze allows the customer to improve the performance of the business and understand where the challenges in the end-to-end workflow are. Providing a mirror for the business of the customer can be extremely valuable and is something customers often are willing to pay for.
The fourth step is comparative analysis. Here, we use data from all customers to provide insights to individual customers. Often, this data can be used to provide insight into the performance of the customer in comparison to similar businesses. These comparisons can be concerned with cost drivers, eg average salary of employees or operating hours of machinery, but also profit drivers, such as average revenue per machine or employee, and so on.
Finally, a highly controversial topic in many companies is to use the data from the primary customer base and monetize this with a secondary customer base. Typical customers of this type of data are hedge funds, which are always looking for ways to create an edge for themselves, but they can also be stakeholders on the edge of the current business. For instance, most trucks have GPS and accelerometers installed, allowing the company providing these trucks to collect road quality data on all the roads where the trucks are active. The question then becomes who is interested in buying this data.
Most companies I work with use data predominantly for defects and quality assurance and fail to exploit the full potential of the data they collect. Once we have frequent data coming back from the field, we can use it to improve system performance, provide insights to our customers and serve additional stakeholder groups. Data is the new oil, Clive Humby wrote in 2017, but if you don’t exploit it, you end up with a bunch of useless storage. Don’t just trust your opinions, but rather trust the data.
Like what you read? Sign up for my newsletter at jan@janbosch.com or follow me on janbosch.com/blog, LinkedIn (linkedin.com/in/janbosch), Medium or Twitter (@JanBosch).
