
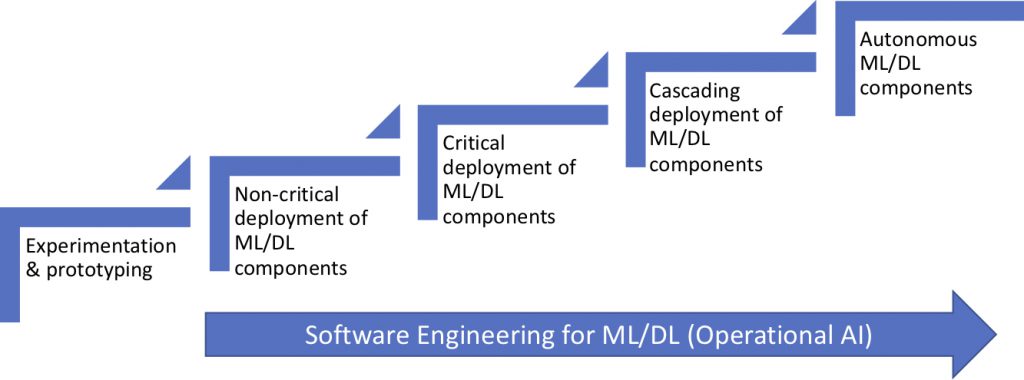
In the latest two articles, I outlined the two phases of adopting machine & deep learning (ML/DL). In the figure below, we show the steps that companies typically evolve through while adopting AI, ML and DL solutions. As shown in the figure, the third step, the subject of this article, is where ML/DL components are deployed for real in products, solutions and services. Although this is where customers are starting to experience the real benefits of AI in your product, it is also where problems might come back to haunt you.
Whenever companies start to deploy a new technology, there initially is trepidation about this and everyone is quite concerned with ensuring that the technology will work well before deployment. The challenge is of course that it is virtually impossible to validate pre-deployment that all edge cases and combinations are accounted for and will not lead to unwanted outcomes.
The validation problem is exacerbated by what Daniel Dennett refers to as the post-intelligent design era. Traditionally, every system put in the hands of users has been designed by a product designer, or rather, a team of designers, that architected the system to do precisely what we designed it to do. In this case, the human provided the the “intelligent design”. When things go wrong, the original designer or other designers can investigate the system and figure out why it didn’t work as it should.
In the case of machine learning and deep learning, we of course build the models, but we really do not know why they are generating the results that they do. These systems are the result of evolution processes, active during training the models, that cause the models to gravitate to specific configurations and weights. Us not understanding how a ML/DL model works is inherent to the situation as we especially apply ML/DL models in situations where we humans have not been able to develop systems that generate satisfactory results, such as image recognition, speech recognition, etc. However, the very fact that we do not really know why a system works may be at the root of situations where a model suddenly behaves very different from what we expected.
The cautionary principle would then dictate that we should not use these ML/DL models in critical deployments. However, I feel that this is an overly simplistic viewpoint in that these models have the potential of providing enormous benefit to mankind. The scope of repetitive and boring tasks now conducted by humans that can finally be automated by the use of AI is enormous. Although many are concerned about the high levels of unemployment of low-skilled workers and I do recognize the need for a transition period in society, history has shown us that every wave of automation has create a broad range of new jobs that consist of far more exciting and intellectually stimulating tasks
Returning to the topic of deploying ML/DL models in parts of our systems where their performance is critical to the success of the system, our research has shown that companies experience major engineering challenges. You can find more details in the papers referenced below and an earlier article, but a high level summary of some of the challenges that the companies in our case studies experience include:
- Training data of sufficient quantity and quality to increase confidence in trained models before deployment.
- Scaling ML/DL deployments in systems with high volumes of users, transactions or events.
- Reproducing results in general, ranging from training to consistency of results of multiple model versions.
- Debugging of deep learning models is challenging as it generally is hard to pinpoint where problems originate.
- Ensuring non-functional requirements such as latency and throughput prove to be difficult to achieve.
- Rapidly GPU architectures and deep learning libraries make it difficult to maintain machine and deep learning models once developed.
- Monitoring and logging of model behaviour is challenging, especially when it comes to recognizing the differences between bugs and features.
- Unintended feedback loops between the system and its users can easily be created when users adjust their behaviour to the system, the system learns the new behaviour, users again adapt, etc.
Concluding, machine and deep learning represent one of the most existing and beneficial technologies for mankind in our current day and age. These systems being exponents of a post-intelligent design era requires us to learn to compensate for the specifics of these systems, especially when deploying in critical contexts. In addition, companies experience significant engineering challenges when deploying ML/DL. There are, however great companies that provide solutions to many of these challenges, such as Peltarion. Mankind, industry, your company and you personally already greatly benefits of AI/ML/DL and we’ve barely scratched the surface of the potential of these technologies. Let’s make sure we capitalize on the potential!
References:
- Lucy Ellen Lwakatare, Aiswarya Raj, Jan Bosch, Helena Holmström Olsson and Ivica Crnkovic, A taxonomy of software engineering challenges for machine learning systems: An empirical investigation, XP 2019 (forthcoming), 2019.
- Arpteg, Anders, Björn Brinne, Luka Crnkovic-Friis, and Jan Bosch. “Software Engineering Challenges of Deep Learning.” In 2018 44th Euromicro Conference on Software Engineering and Advanced Applications (SEAA), pp. 50-59. IEEE, 2018.
To get more insights earlier, sign up for my newsletter at jan@janbosch.com or follow me on janbosch.com/blog, LinkedIn (linkedin.com/in/janbosch) or Twitter (@JanBosch).
