
(Image credit: pixabay)
This week I spent in the lovely city of Prague, attending the SEAA 2018 conference. The main reason for attending was that I had the opportunity to present a paper that I co-authored with colleagues from Peltarion about the software engineering challenges of deep learning. Peltarion offers an amazing platform for building deep learning systems and if you’re interested in AI/ML/DL, you should really check out their platform.
The team from Peltarion that I wrote the paper with has several decades of experience in building deep learning systems and come from successful (and now large) startups in Sweden and have worked for a variety of high-profile customers from around the world. Their experiences and insights provided an excellent basis for a paper that identifies the key software engineering challenges associated with building mission-critical, production-quality deep learning systems.
Surprisingly, although many companies are experimenting with deep learning and build prototypes using tools like TensorFlow and PyTorch, few realize the challenges associated with taking such a prototype and productifying it are many and are likely to cause the whole initiative to fail. This is not an empty threat as we have several examples of companies trying to go it alone without a proper platform. The software engineering challenges of deep learning are real and hard.
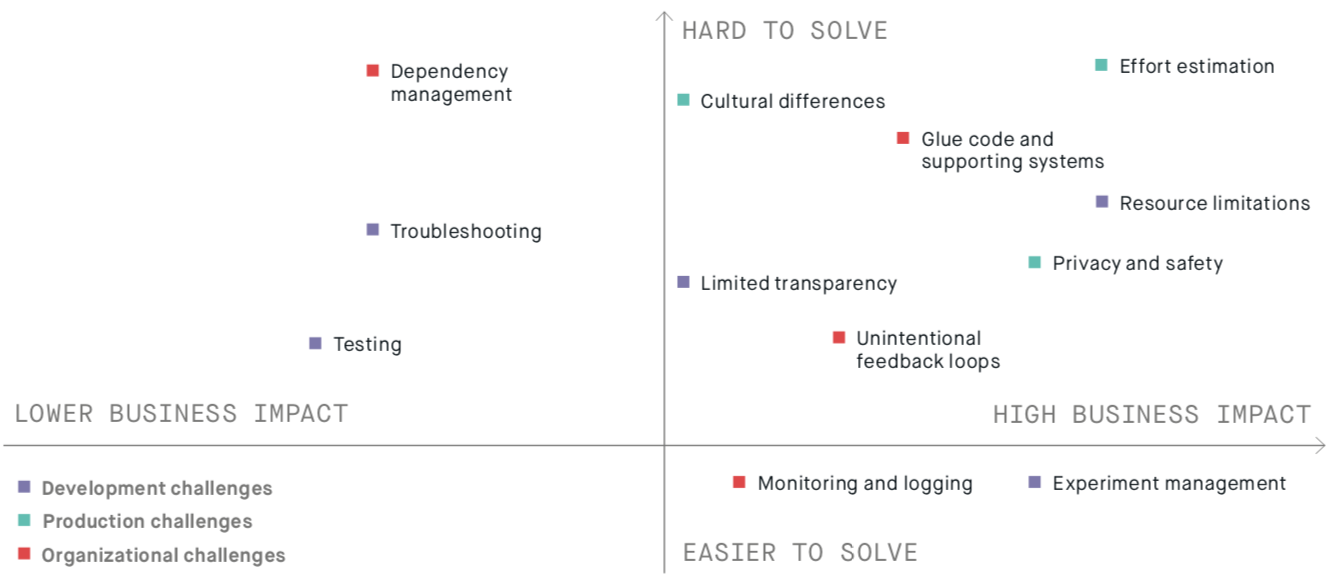
Although you can download the slides here and the paper here, I thought I’d provide a brief overview of the topics that I presented. We identify three categories of challenges, associated with development, production and organization.
We discuss five development challenges:
- Experiment Management: how to keep track of all the contextual factors (e.g. HW, platform, etc.) when running many experiments.
- Limited Transparency: neural networks give little insight how why and how they work.
- Troubleshooting: large libraries, lazy execution and lack of tooling complicate solving defects enormously.
- Resource Limitations: large data sets and complex models cause the use of distributed architectures that further complicate experiment management and troubleshooting and increase cost, required knowledge and time.
- Testing: testing of data is very complicated and there is little tooling. Also testing models and the underlying infrastructure is very complex.
The production challenges we identified include:
- Dependency Management: GPU hardware and SW platforms are improving and evolving very rapidly and software often encodes contextual knowledge for performance reasons.
- Monitoring and Logging: models are often retrained frequently and behaviour may change. Distinguishing between bugs and improvements is difficult.
- Unintended Feedback Loops: real world may adopt to the model, rather than the other way around.
And finally, the organizational challenges we discuss are the following:
- Effort Estimation: we fundamentally don’t know how long it will take to develop an acceptable model (and if it will ever happen).
- Privacy and Data Safety: as we often don’t know how neural networks work, it is difficult to guarantee that no personal or private data is stored in the network.
- Cultural Differences: data scientists and software engineers often have very different drivers and ways of working.
Concluding, current tools, such as TensorFlow and PyTorch, make it very easy to build deep learning prototypes. Building mission-critical, production quality systems out of these prototypes proves to be a significant software engineering challenge and in the paper and presentation my colleagues at Peltarion and I present the key development, production and organization challenges. Of course, it goes without saying that Peltarion offers a platform that solves many, if not all of these challenges, and offers – what we call – Operational AI. However, the purpose of this article is not to be a sales pitch, but to raise awareness. Engineering deep learning systems is hard!

Hi, Thanks for sharing wonderful articles…
thanks for sharing nice information and nice article and very useful information…..
Thank you for sharing this wonderful information.
Thanks again for sharing your encouraging experience
Thanks again for sharing your encouraging experience