
In last week’s article, I outlined the first phase of adopting machine & deep learning (ML/DL) which is concerned with experimentation and prototyping. In the figure below, we show the steps that companies typically evolve through while adopting AI,ML and DL solutions. As shown in the figure, the next step is the careful use of ML/DL in products, solutions and services in a non-critical capacity. Although this is the point where ML/DL models are put in operation and customers can experience the benefits, initially companies are careful about the use of these models as these are viewed as unpredictable. Consequently, the deployment is only done for non-critical functionality in the offering.
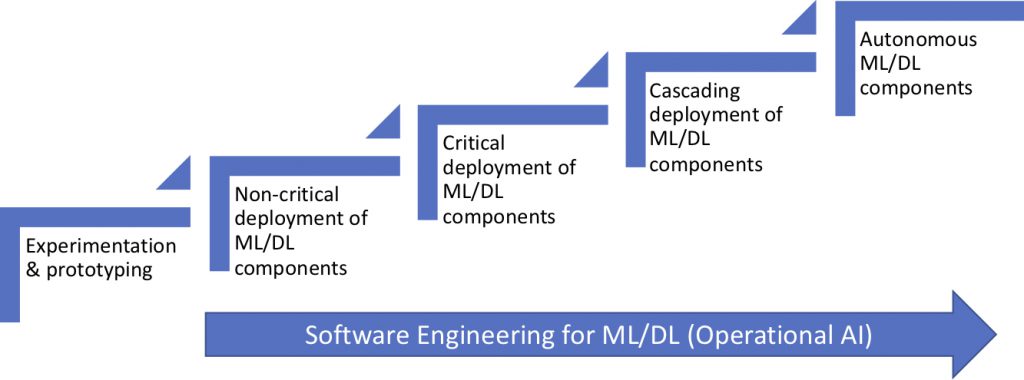
Starting with non-critical deployment of ML/DL components is critical to learn about the challenges the company might experience as it moves to the use of ML/DL components in more critical deployments where potentially exceptional, unpredictable and erratic behavior severely undermines customer value derived from products, solutions and services
In our research (see reference below), we have identified that companies that have reached this step experience a number of main challenges. These challenges are associated with the four stages of working with ML/DL components, i.e. assemble dataset, create model, train & evaluate and deploy. Below we discuss the key challenge in each stage.
During the first stage where the company needs to assemble the data set, organizations experience three main challenges. The first is that data that would be needed for training and validation is spread out across the company and needs to be collected from a variety of different data silos. The associated challenge is of course that the data from different silos may easily use different semantics and schemes for similar or related data items. Second, in most cases, ML/DL models required labelled models for supervised learning. Although the company may have the data available, it often is far from obvious to deduce what labels need to be associated with each data item. Finally, available data sets typically are assembled for specific purposes, causing the data to not be representative of reality, but rather contain a significant overrepresentation of specific cases or data.
During the second stage the engineers are concerned with creating a model that is aligned with the problem at hand and that generates the desired output, such as a classification or prediction. Whereas during experimentation and prototyping, any model that achieves a some level of accuracy is acceptable, in this step the model will be exposed to customers. This requires the quality of the model to be higher, but most companies lack the skills and competencies to improve on a basic model. Doing so requires the ability to analyse which elements, algorithms or layers in the model cause the lack of accuracy as well as the ability to take corrective action to address the problem.
The training and evaluation stage is concerned with training and evaluating the model defined in the previous stage. The key challenge here often is the availability of data for training and evaluation. Although approaches such as k-fold cross-validation exist and more experienced data scientists will know how to use these, in practice the company is in the early stages of adopting AI/ML/DL solutions and the amount of available talent tends to be limited.
The deployment stage is on the receiving end of the challenges experienced in the previous stages and this frequently results in a significant training-serving skew. This means that the model performs significantly worse in deployment than in training. This is typically caused by a difference between the data used during training and the data served during operations.
Concluding, companies evolve through a number of steps when adopting AI/ML/DL models. In this article we discussed the challenges that companies experience in the second step where the company deploys the first ML/DL models in non-critical parts of products, solutions and services. The main challenges are concerned with assembling labelled data sets of sufficient quality and quantity as well as the skills of engineers to improve underperforming models. These challenges may cause a significant training-serving skew when models get deployed.
The purpose of this article was to outline the challenges in order to help companies adopt ML/DL solutions while avoiding the traps that we outlined. Machine and deep learning offer fabulous technology that can provide incredible benefits. However, it comes with significant engineering challenges some of which we have outlined in the above. Good luck!
Reference: Lucy Ellen Lwakatare, Aiswarya Raj, Jan Bosch, Helena Holmström Olsson and Ivica Crnkovic, A taxonomy of software engineering challenges for machine learning systems: An empirical investigation, XP 2019 (forthcoming), 2019.
To get more insights earlier, sign up for my newsletter at jan@janbosch.com or follow me on janbosch.com/blog, LinkedIn (linkedin.com/in/janbosch) or Twitter (@JanBosch).

I don’t even know how I ended up here, but I thought this post was
good. I do not know who you are but certainly you are going to a famous blogger if you are not already 😉 Cheers!