
This week I got the opportunity to speak at the initiative seminar organized by the Chalmers AI Research center (CHAIR). The key message in my presentation was that working with artificial intelligence (AI) and specifically machine & deep learning (ML/DL) constitutes a major software engineering challenge that is severely underestimated by companies that start to experiment with machine and deep learning.
Although I have discussed some of the challenges in an earlier blog post, we have continued to conduct research in this area and we have collected additional data concerning the specific challenges. In addition, we have developed a model that captures how companies typically evolve in their adoption of AI/ML/DL. As shown in the figure below, we show the steps that companies typically evolve through. In this and the upcoming posts, I intend to discuss the challenges associated specifically with each step. This is based on an article that recently was accepted for publication in the proceedings of the XP 2019 conference.
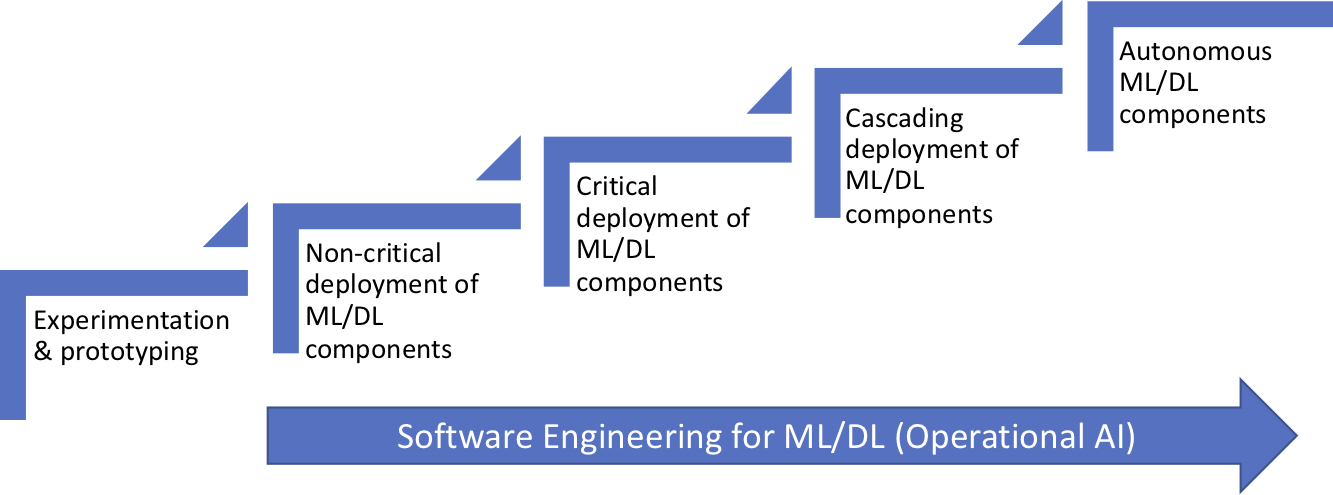
As the figure illustrates, the first step that most companies engage in is experimentation and prototyping. In this case, the work on machine & deep learning models is conducted purely in-house and without any connection to the products and services that the company offers to its customers. The work with basically any ML/DL approaches follows the process shown in the figure below. Basically, there are four stages, i.e. assemble datasets (or data pipes), create models, train & evaluate and, finally, deployment. There are two iterative processes. The inner loop is concerned with the typical activity of creating a model, training it, evaluating it and then tweaking the model with the intent of increasing accuracy and reducing error rates. The outer loop illustrates the periodic or continuous retraining of models based on the most recent data and the subsequent continuous deployment of models into operation.

Our research shows that companies experience various challenges in each of the steps of the process and that these challenges depend on the evolution stage where the company finds itself. For companies in the experimentation and prototyping stage, I’ll describe the key challenge in each process step.
For the “assemble datasets” step (which in later stages becomes the data pipelines step), the very activity of assembling the right datasets for training and validation purposes often proves to be a significant challenge. Although all companies tend to drown in data, this data often has unclear semantics and the way it has been collected is often unclear, resulting in datasets that are not necessarily representative of the operational data that would be used during operations. As a data point: a company that I visited recently claimed that more than 90% of all effort in the data analytics team went to assembling datasets and setting up reliable data pipelines. Although easily underestimated, this is a major challenge.
The “create models” step is concerned with creating ML/DL models that perform well for the data that the problem domain is characterised by. As a well performing model is highly dependent on the characteristics of the input data, any issues during the previous step automatically affect the quality of the model. In addition, especially in this early stage, often companies experience a lack of talent with experience, exacerbating the situation.
The “train & evaluate” step typically struggles with the fact that establishing the problem specification and desired outcome as well as having datasets that capture a solid ground truth that can be used as a reference for training and evaluating models. As a consequence, it can prove to be difficult to determine which model is superior as well as whether any of the models is of sufficient accuracy.
Due to the nature of this stage, that is no deployment mechanism yet. The challenges with setting up a deployment mechanism are discussed in future articles discussing the higher stages in the evolution model.
Concluding, the first stage in adoption ML/DL in your products, systems and solutions is concerned with experimentation and prototyping. During this stage, the predominant challenge is the establishment of datasets of sufficient quality as a basis for model creation, training and evaluation. These datasets need to be representative of the data that will, during operations, come through the data pipelines. Our research shows that companies struggle with data quality in this stage and the subsequent steps in the development process are negatively affected. So, get going with ML/DL yesterday, but focus your energy where it counts: high-quality data sets.
Reference: Lucy Ellen Lwakatare, Aiswarya Raj, Jan Bosch, Helena Holmström Olsson and Ivica Crnkovic, A taxonomy of software engineering challenges for machine learning systems: An empirical investigation, XP 2019 (forthcoming), 2019.
To get more insights earlier, sign up for my newsletter at jan@janbosch.com or follow me on janbosch.com/blog, LinkedIn (linkedin.com/in/janbosch) or Twitter (@JanBosch).

This is amazing! Deep learning is the future
Hello, our company has recently started to provide deep learning machine vision software/systems (Cognex ViDi) to medical device manufacturers here in California. We do provide Validation services as part of our service offering, but are struggling to provide Validation packages for DL that QC departments are comfortable with. They want to have some degree of certainty that the CNN is stable long term; the whole “black box” of CNNs versus traditional rule based machine vision software is the problem. Can you point to some resources that may assist us in developing a Validation approach specific to the challenges of DL? Thanks.