
In recent columns, I’ve been sharing my view on the quality of the data that many companies have in their data warehouses, lakes or swamps. In my experience, most of the data that companies have stored so carefully is useless and will never generate any value for the company. The data that actually is potentially useful tends to require vast amounts of preprocessing before it can be used for machine learning, for example. As a consequence, in most data science teams, more than 90 percent of all time is spent on preprocessing the data before it can even be used for analytics or machine learning.
In a paper that we recently submitted, we studied this problem for system logs. Virtually any software-intensive system generates data capturing the state and significant events in the system at important points in time. The challenge is that, on the one hand, the data captured in logs is intended for human consumption and, consequently, contains a high variability in the structure, content and type of the information for each log entry. On the other hand, the amount of data stored in logs often is phenomenally large. It’s not atypical for systems to generate gigabytes of data for even a single day of operations.
The obvious answer to this conundrum is to use machine learning to derive the relevant information from the system logs. This approach experiences a number of significant challenges due to the way logs are generated. Based on our research in literature and company cases, we identified several challenges.
Due to the nature of data generation, the logs require extensive preprocessing, reducing the value. It’s also quite common that multiple system processes write into the same log file, complicating time series analysis and other machine learning techniques assuming sequential data. Conversely, many systems generate multiple types of log files and establishing a reliable ground truth requires combining data from multiple log files. These log files tend to contain data at fundamentally different levels of abstraction, complicating the training of machine learning models. Once we’re able to apply machine learning models to the preprocessed data, interpretation of the results often requires extensive domain knowledge. Developers are free to add new code to the system that generates log entries in ad-hoc formats. The changing format of log files complicates the use of multiple logs for training machine learning models as the logs aren’t necessarily comparable. Finally, any tools built to process log files, such as automated parsers, fail unpredictably and are very brittle, requiring constant maintenance.
We studied the problem specifically for system logs, but my experience is that our findings are quite typical for virtually any type of automated data generation. Although this is a huge problem for almost all companies that I work with and enormous amounts of resources are spent on preprocessing data to get value out of it, it’s a losing battle. The amount of data generated in any product, by customers, across the company, and so on, will only continue to go up. If we don’t address this problem, every data scientist, engineer and mathematician will soon be doing little else than preprocessing data.
The solution, as we propose in the paper, is quite simple: rather than first generating the data and then preprocessing it, we need to build software to generate data in such a format that preprocessing isn’t required at all. Any data should be generated in such a way that it can immediately and automatically be used for machine learning. Preferably without any human intervention.
Accomplishing this goal is a bit more involved than what I can outline in this post, but there are a number of key elements that I believe are common for any approach aiming to achieve this. First, all data should be numerical. Second, all data of the nominal type (different elements have no order nor relationship to each other) should be one-hot encoded, meaning that the elements are mapped to a binary string as long as the number of element types. Third, data of the ordinal type can use the same approach or, in the case of non-dichotomous data, use a variety of encodings. Fourth, interval and ratio data needs to be normalized (mapped to a value between 0 and 1) for optimal use by machine and deep-learning algorithms. Five, where necessary, the statistical distribution of the data needs to be mapped to a standard Gaussian distribution for better training results.
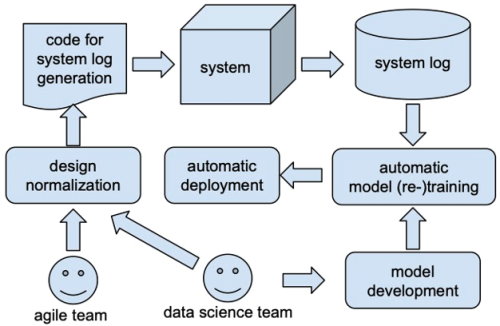
Accomplishing this at the point of data generation may require engineers and developers to interact with data scientists. In addition, it calls for alignment across the organization, which hasn’t been necessary up to now. However, doing so allows companies to build systems that can fully autonomously collect, train and retrain machine learning models and deploy these without any human involvement (see the figure).
Concluding, most data in most companies is useless because it was generated in the wrong way and without proper structure, encoding and standardization. Especially for the use of this data in training machine learning models, this is problematic as it requires extensive amounts of data preprocessing. Rather than improving our data preprocessing activities, we need to generate data in a way that removes the need for any preprocessing at all. Data scientists and engineers would benefit from focusing on how data should be generated. Rather than trying to clean up the mess afterward, let’s try to not create any mess to begin with.
For more information, you can read the paper that I mentioned here:
https://arxiv.org/abs/2001.10794
To get more insights earlier, sign up for my newsletter at jan@janbosch.com or follow me on janbosch.com/blog, LinkedIn (linkedin.com/in/janbosch) or Twitter (@JanBosch).
