
During the big data era, one of the key tenets of successfully realizing your big data strategy was to create a central data warehouse or data lake where all data was stored. The data analysts could then run their analyses to their hearts’ content and find relevant correlations, outliers, predictive patterns and the like. In this scenario, everyone contributes their data to the data lake, after which a central data science department uses it to provide, typically executive, decision support (Figure 1).
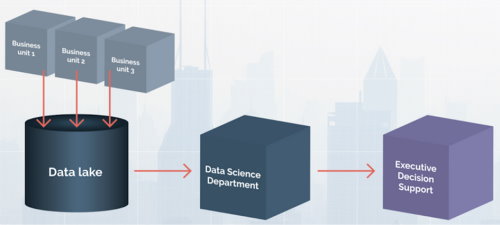
Although this looks great in theory, the reality in many companies is, of course, quite a bit different. We see at least four challenges. First, analyzing data from products and customers in the field often requires significant domain knowledge that data scientists in a central department typically lack. This easily results in incorrect interpretations of data and, consequently, inaccurate results.
Second, different departments and groups that collect data often do so in different ways, resulting in similarly looking data but with different semantics. These can be minor differences, such as the frequency of data generation, eg seconds, minutes, hours or days, but also much larger differences, such as data concerning individual products in the field vs similar data concerning an entire product family in a specific category. As data scientists in a central department often seek to relate data from different sources, this easily causes incorrect conclusions to be drawn.
Third, especially with the increased adoption of DevOps, even the same source will, over time, generate different data. As the software evolves, the way data is generated typically changes with it, leading to similar challenges as outlined above. The result is that the promise of the big data era doesn’t always pan out in companies and almost never to the full extent that was expected at the start of the project.
Finally, to gain value from big data analytics requires a strong data science skillset and there simply aren’t that many people around that have this skillset. Training your existing staff to become proficient in data science skills is quite challenging and most certainly harder than providing machine learning education to engineers and developers.
Many in the industry believe that artificial intelligence applications, and especially machine and deep-learning models, suffer from the same challenges. However, even though both data analytics and ML/DL models are heavily based on data, the main difference is that for ML/DL, there’s no need to create a centralized data warehouse. Instead, every team, business unit or product organization can start with AI without any elaborate coordination with the rest of the company.

Each business unit can build its own ML/DL models and deploy these in the system or solution for which they’re responsible (Figure 2). The data can come from the data lake or from the local data storage solutions, so you don’t even need to have adopted the centralized data storage approach before starting with using ML/DL.
Concluding, AI is not data analytics and doesn’t require the same preconditions. Instead, you can start today, just using the data that you have available, even if you and your team are just working on a single function or subsystem. Artificial intelligence and especially deep learning offer amazing potential for reducing cost, as well as for creating new business opportunities. It’s the most exciting technology that has reached maturity in perhaps decades. Rather than waiting for the rest of the world to overtake you, start using AI and DL today.
This article was inspired by a discussion with Luka Crnkovic-Friis, CEO of Peltarion.
To get more insights earlier, sign up for my newsletter at jan@janbosch.com or follow me on janbosch.com/blog, LinkedIn (linkedin.com/in/janbosch) or Twitter (@JanBosch).

I feel very grateful that I read this. It is very helpful and very informative and I really learned a lot from it.
data scientist training in malaysia