![]()
This week I was in Madrid to present a keynote at a workshop around variability management (VAMOS 2018). It was a fun event and to some extent a trip down memory lane as I was part of the early research community that systematically started to work on software variability management in the early 2000s. We organized workshops, made it an increasingly important topic in the Software Product Line Conference series (this year it’s in Gothenburg), I had PhD students working on this (email me if you want to read their thesis), edited books on the topic (e.g. this one), companies were founded (not by me!) to provide tools to address this problem, etc. In short, it was a next, big upcoming topic in software engineering.
As I was preparing the keynote and presented it at the event, however, I realized that all the problems that we were studying in the early 2000s still are problems today. And upon reflection, I realized that the companies that I work with today are experiencing the same challenges as the companies that I worked with almost two decades ago did. How, in heaven’s name, have we failed to make progress in an area that is notoriously costly, complex and frustrating to handle?
In principle, variability management is simple. There are two sides, i.e. the “problem domain”, where we outline what features and functions our system can offer, and the “solution domain” where we have the technical realization of the system, including variation points and variants associated with each variation point. On top of this, we express constraints, both in the problem domain and in the solution domain. For instance, some features cannot be combined with other features whereas in other cases selecting one feature requires that another feature is present as well. In the solution domain, some features are implemented such that they can only be selected or de-selected together. This may lead to a situation that the final “problem domain” variability model reflects solution domain constraints as well.
In my experience there are three main reasons that cause this simple model to fall apart in industrial contexts. First, the solutions that are available often fail to support scale. Research prototypes show the principles using a dozen or so variation points. Industrial practice, however, shows that many systems contain thousands if not TENS of thousands of variation points. Conceptually and practically our methods, frameworks and tools are unable to handle that scale.
Second, in engineering but especially in product management, sales and general management there is a gross underestimation of and lack of respect for the complexity of variability management. One consequence, among many, is that it often results in situation where engineers are forced to quickly add some customer specific functionality to a system that is otherwise set up for proper variability management. As the customer specific functionality should not be available for others, it naturally should be modeled in variation points and associated variants. Under time pressure, engineers then easily opt to create a separate customer-specific branch of the software. This is of course the first step on the highway to hell as before you know it, every customer will have its own branch and you’ll slide into a consulting business rather than a product business.
Third, as eager as organizations are to add variants and variation points, as reticent they are about removing variants and variation points when these no longer serve a business purpose. A variation point or variant, once introduced, is hardly ever removed. This is interesting as in embedded systems companies, the systems architects often work hard to restrict and reduce variation for physical components but ignore or demand more software variability. Also, as many companies fail to collect configuration data for their customers, it is often unknown if there still is a customer out there using a certain variant. As management often does not realize the cost of maintaining a variation point and its associated variants, the number of variation points only grows.
With all these challenges, how do companies still get products out the door? In my experience, the most advanced companies often use homegrown solutions (often called some variation of “configurator”). In combination with process discipline around managing variation points and variants and significant amounts of automated testing in a continuous integration chain, this allows these companies to support a broad configuration space from a single code base. The most immature companies tend to end up with customer branches, sometimes lots of them, and vast amounts of effort to replicate functionality that is required by all customers. However, although these problems solve the pre-deployment variability, these do not solve the post-deployment variability.
For a more general solution, however, in my experience there are four topics that provide material benefit. First, the Three Layer Product Model (3LPM) is a very effective basis for managing the introduction, evolution and removal of variability. As shown in figure 1 below, the notion of 3LPM is to organize functionality in three layers, i.e. a commodity functionality layer, a differentiating functionality layer and a layer for innovation and experimentation.
For variability management, the innovation layer should not be allowed to add variants and variation points. The reason is that most innovations fail and we do not want our software to be littered with useless variation points and variants. For the differentiation layer, we invest in adding and evolving variation points as it allows us to serve different customer segments and geographies better, support multiple external platforms, etc. Finally, in the commodity layer, our focus should be on removing variation points as the business value proposition for maintaining variation points and variants for commodity functionality is no longer valid.
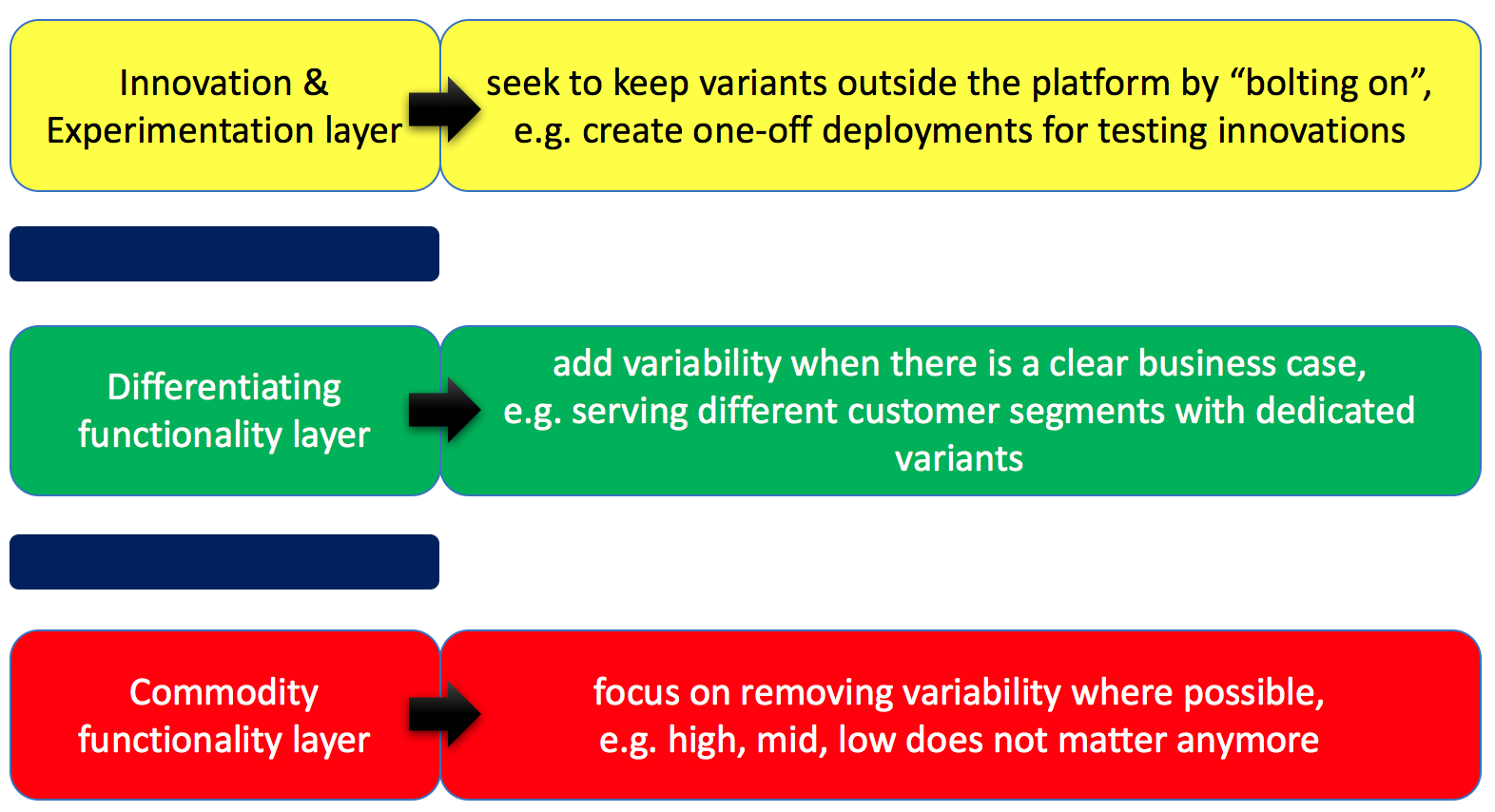
Figure 1: Variability management focus in each of the 3LPM layers
Second, in an earlier blog post, I outlined an approach for automatically generating and testing software for all products automatically as prerequisite for continuous deployment. Even if this requires the development of an inhouse tool, it will remove many of the inefficiencies associated with variability management. As shown in figure 2, this approach will ensure that the organization does not fall back into building customer-specific solutions.
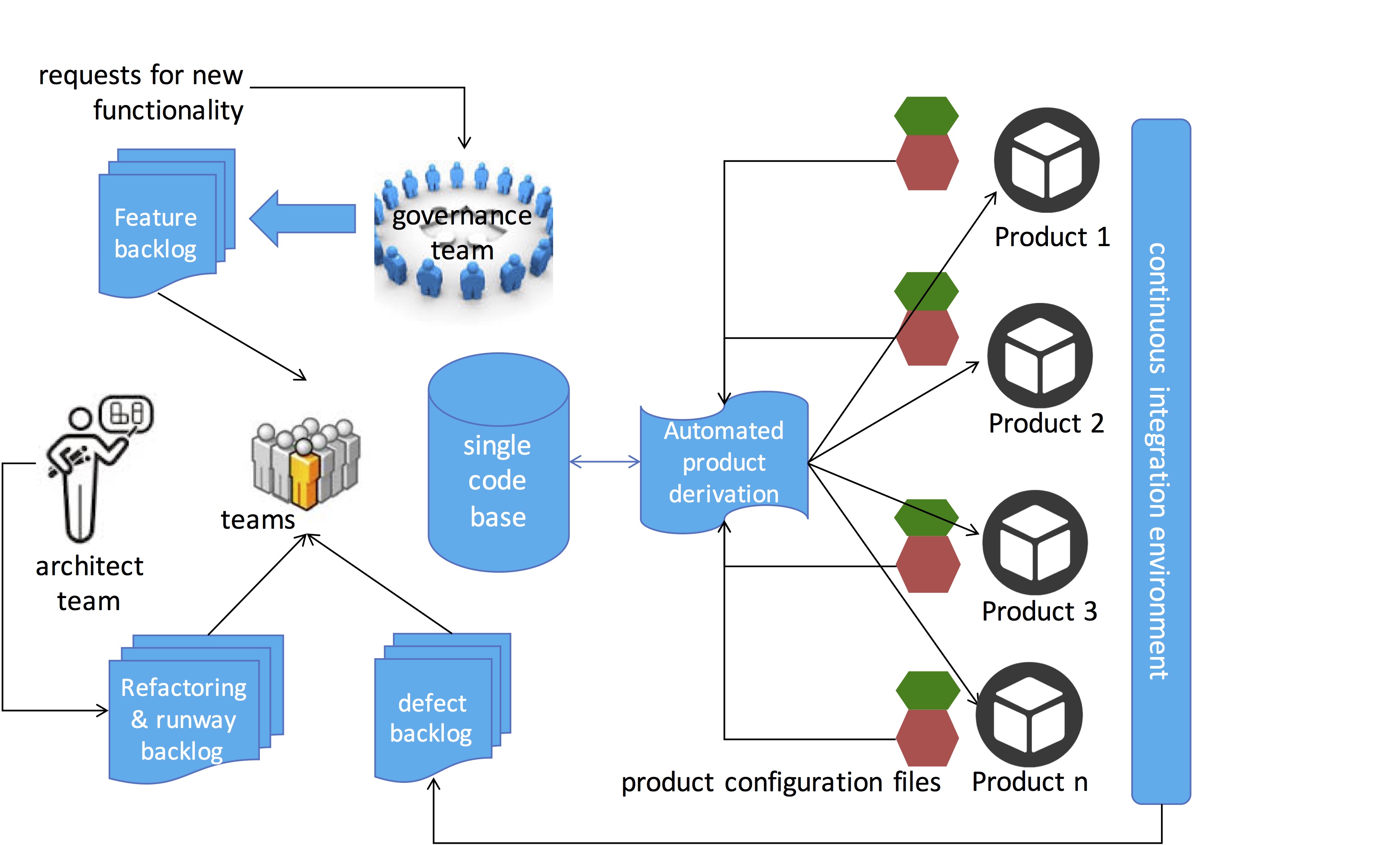
Figure 2. Managing variability and automated product derivation
Third, carefully design a configuration interface that customers will get access to. In several cases, I have experienced a situation where a company was completely unable to control their variability model as its customers had built their configuration tools around its, often poorly designed, variability model. This meant the company, for years and years, had to carry the cost of a poorly designed configuration interface. Instead, design a customer facing configuration interface that is as much as possible expressed in “problem domain” concepts, so that you maintain the flexibility to change the solution domain variability.
Finally, as a fourth strategy, convincing the non-technologists in the company as well as the traditionalists in engineering, often it is required to build some kind of economic model to outline the cost of variability management. Although I have not yet managed to create a generic model, creating a company specific model that estimates the lifetime cost of introducing a variation point, introducing a variant, the running cost of maintaining and evolving variation points and variants and finally the cost of removal should be explicitly available as this is the only counterweight that one can offer against a spur-of-the-moment, let’s make the customer happy kind of decision.
Concluding, software variability management is still hard, complex and expensive. It is a challenge often severely underestimated by business and engineers alike. However, there are solution approaches that one can take to address the problem and, if not solve it, at least make it significantly easier to handle. Unfortunately, it often does not allow for a standard recipe to be applied, but rather it needs a dedicated, company-specific approach to address it. Of course, feel free to reach out if you feel I can help. But get going on this challenge as soon as feasible as it is hard and not only technical in nature. It requires significant behavioral changes from the organization as well. Enjoy your variance!
To get more insights earlier, sign up for my mailing list at jan@janbosch.com or follow me on janbosch.com/blog, LinkedIn (linkedin.com/in/janbosch) or Twitter (@JanBosch).
