
In this series on the AI-driven company, we’ve discussed the challenges that companies experience in becoming more AI-driven as well as the implications for business processes and for product R&D. The general pattern is that AI starts off as support for and augmentation of humans and, over time, becomes the main executor, with humans taking more of the role of a supervisor.
However, AI isn’t just augmenting business and development processes. It’s increasingly becoming embedded in the products themselves as well. That brings us to the third maturity ladder: the AI-enabled product.
For products, however, “AI-driven” or “AI-enabled” means very different things at different maturity levels. In our interview study, we saw a pattern where companies evolved their use of AI and specifically machine learning (ML) models through a number of stages: static ML → dynamic ML → multiple ML → continuous ML → AI-first products.
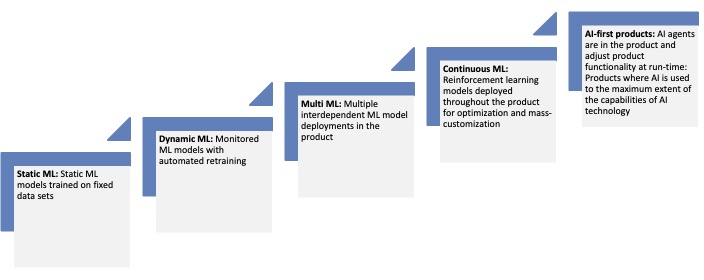
Figure: AI-enabled product maturity model
In the first step, companies use one or more single-purpose, pre-trained ML models that are embedded in products. For example, a company may use a pre-trained image classifier or recommendation model that’s updated infrequently. Although this is a great first step, because the models are trained offline and need to be manually updated in the product, we typically see quite fixed, static functionality in the ML models. From a business perspective, this means that the model may provide differentiation when first introduced, but is likely to commoditize quickly as competitors can easily catch up.
In the second step, dynamic ML models, things become more context-aware in many ways. Here, models can adapt to user context or environment at runtime and may use the data the models collected for limited retraining. The challenge here is that we need to collect both the data and the outcome of the model, as retraining can’t be applied otherwise. As examples, we may see real-time personalization of content or adaptive cruise control that adjusts to conditions, such as human interaction with the system. Typically, these applications use some data feedback and offer some online learning, but aren’t yet fully continuous. This level has benefits as it can be used to improve stickiness and user experience, but adaptivity is still limited.
In the third step, we engineer products where multiple ML models are orchestrated to deliver on a complex task or set of tasks. For example, we could build a smart assistant that combines speech recognition, intent classification and personalization. Such a system would require multiple ML models to interact to realize the expected behavior. This, of course, requires coordination between models, often through API-driven integration, which leads to more complex architectures. The benefit of this level is that it’s feasible to build much higher value offerings for customers, but it calls for significant engineering competence due to the increased complexity of the final system.
In the fourth step, we’re entering the continuous machine learning stage, where systems are constantly improving. To achieve this, the system needs automated pipelines for retraining, deployment and monitoring, so the model or models keep getting better as they’re fed fresh data. An example would be a fraud detection system that learns from every new incident. At this level, we can also see the deployment of reinforcement learning as well as federated reinforcement learning, where fleets of systems jointly learn in real-time and improve faster than what each individual system could do by itself. Technically, this requires MLOps at scale, including full automated retraining of models as well as A/B testing of model variants to avoid significant drops in performance. At this stage, the data and AI flywheel really takes off as these kinds of systems exhibit fast learning cycles that may easily result in a competitive moat as the system keeps learning, making it hard for competitors to catch up.
At the final step of AI-first products, rather than extending existing solutions with AI capabilities, we conceive products around AI from the outset. Typical examples of this include autonomous vehicles and generative co-pilots. In the first case, the perception and control are entirely AI-driven and hence the product is architected around the ML models required for successful operation. In the second case, the co-pilots typically incorporate the LLMs or LMMs required for successful operation. In that sense, the product architecture is structured around the ML components and data and AI are at the core of the product. I expect that we’re going to see entirely new types of products that we’re unable to imagine today.
Of course, climbing the AI-enabled product maturity ladder isn’t without a fair set of challenges. Some of the ones mentioned in our interview study and observed in our research include managing the data infrastructure and governing effectively, as well as ML model lifecycle management and MLOps. Then, for companies subject to regulatory compliance, and which company isn’t these days, combining these approaches with staying compliant requires significant effort. Finally, especially the higher levels in our maturity model call for a significant shift in organizational mindset – rather than focusing on features, we start from an AI-first, zero-based position where we can conceive entirely new offerings.
The third and final maturity ladder in this series is concerned with the product itself. We identified and discussed the five steps that companies move through: static ML, dynamic ML, multiple ML, continuous ML and AI-first products. The question is: where are you on this ladder? And, obviously, what are you going to do to climb it? To end with a quote by one of my favorite science fiction authors, William Gibson, remember that “the future is already here – it’s just not evenly distributed.”
Want to read more like this? Sign up for my newsletter at jan@janbosch.com or follow me on janbosch.com/blog, LinkedIn (linkedin.com/in/janbosch) or X (@JanBosch).
