Over the last two decades or so, I have worked with companies on their R&D efficiency. R&D efficiency, to me, is concerned with creating as much value as possible for every unit of R&D effort (person hours, currency, etc.). Value can be created in many ways, but a pretty good approximation is the frequency of use of a feature across the user base.
Measuring feature usage is pretty much the norm in the Web 2.0 and SaaS world, but in many of the other companies R&D has little or no understanding of the actual use of features in their systems. In our research we have studied feature usage in different companies and software systems and in general our research shows that around half of the features are hardly ever if ever used.
So, not only do 9 out of 10 in R&D work on commodity functionality, as I shared in last week’s blogpost. Of the small amount of resources that is allocated to adding new functionality, which obviously intended to be differentiating, half of that functionality turns out to be a waste. Half of the features are used very little and do not provide the expected value. For instance, in the picture below, we captured frequence of feature use and it’s clear that the majority of features are used very infrequently.
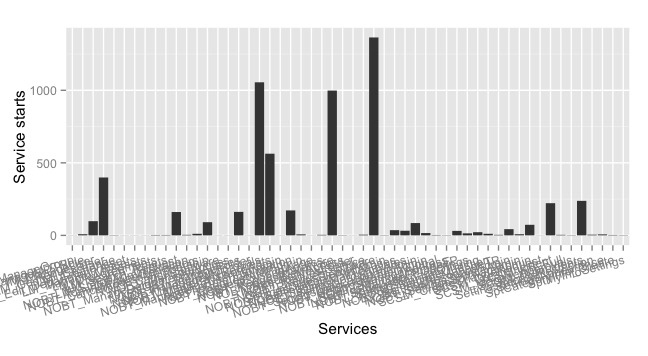
Figure 1: overview of feature usage for a software system
In many companies, product management is a separate organization that communicates with the R&D organization through requirement specifications. In response, the R&D organization just builds the functionality according to the specification. This process is based on the, frequently qualitative, input that product managers receive from customers. This means that R&D builds according to the specifications with very little understanding of how the functionality will be used by customers.
A second challenge is that many organizations rely on what customers say they want, rather than base decisions on the actual behavior of customers. Especially in B2B markets, customers have clear opinions about what they want to see in new product releases. However, the actual behavior of customers and the effects of new functionality on system behavior is frequently very different from the expectations. There are many examples of the gap between espoused theory and theory in use.
The root cause for these challenges is the lack of data and use of data in the end-to-end product development process. Although companies typically collect vast amounts of data, this data is not useful for tracking feature usage. And when I work with R&D teams, the awareness and understanding of using data for anything but quality assurance and troubleshooting is highly limited. We have done research on this topic for years now and have several interesting models and other results. One example is, for instance, the HYPEX model shown in the figure below.
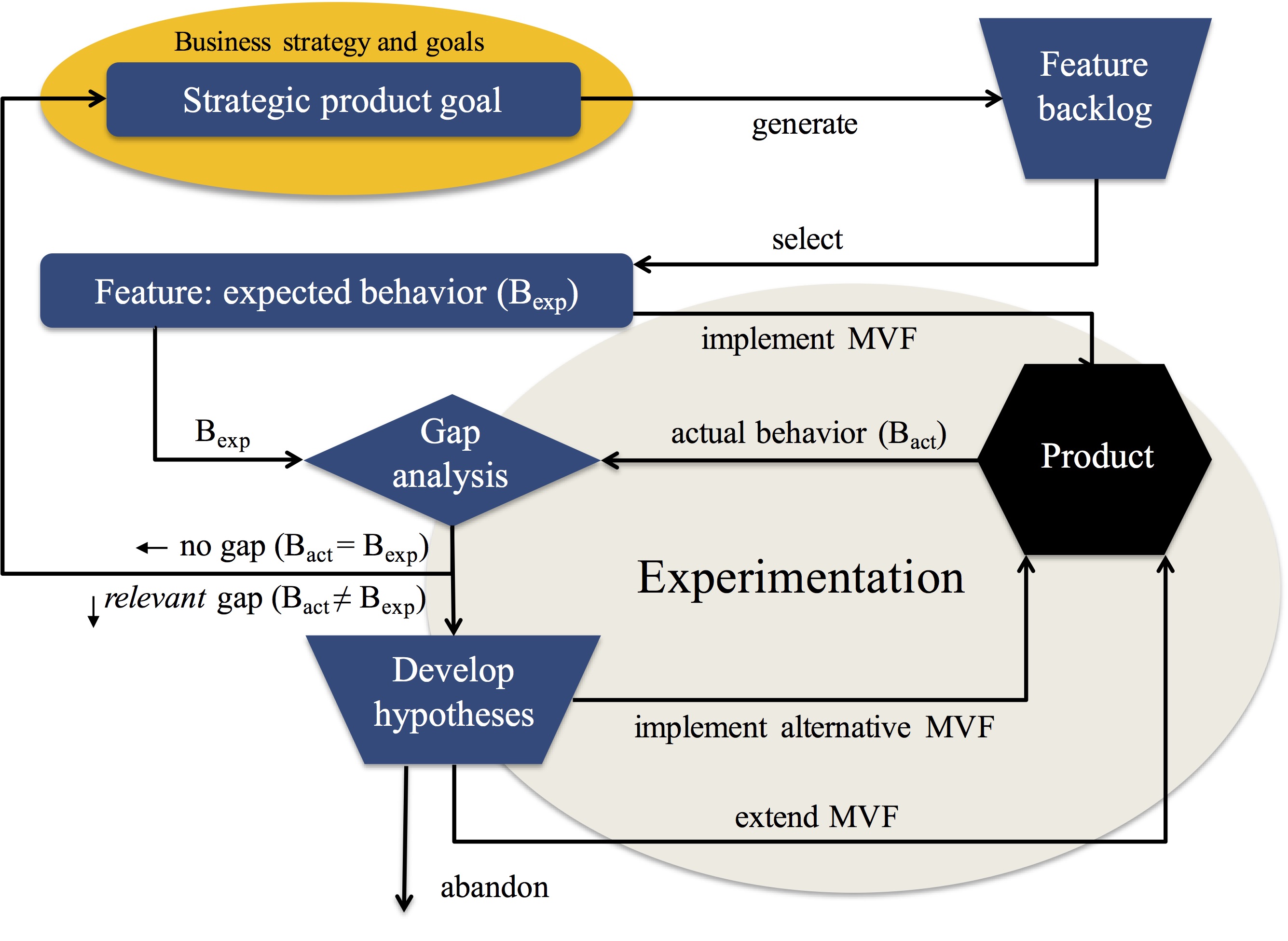
Figure 2: The HYPEX model
To address this, over the last months I’ve written a short book on using data to build better products. The book describes the basics of working with data in R&D and uses a fictive startup team working with data for their embedded product. The book focuses on three steps. The first step is understanding feature usage. The second step is concerned with optimizing features to deliver the intended outcome. The third step is about modeling the intended value of a feature and then tracking the relevant indicators during development and after deployment. The book illustrates these steps with hands-on examples and a running example.

Figure 3 : Book cover
This week, the book became available on Amazon and CreateSpace in paperback and kindle formats, so take a look and consider getting a copy. I would very much appreciate it!

Yep. Feature overload is a classic. And tricky. Getting rid of stuff is one of the hardest things a Product Manager has to do. I like this quote from Des Traynor, speaking of how dangerous it is to compare our feature set to that of the competitor’s: “We are delivering yesterdays broken technology tomorrow.” (https://www.youtube.com/watch?v=9AM6QQlgLSQ&t=05m40s)
Jan, what are some of the methods you’ve found most effective in evaluating customer’s _actual_ value received from a feature?
Thanks for the comment, Martin! The best starting point, I believe, is to start tracking actual feature usage by instrumenting your system. Once that is established for the set of features that you offer in the product, the next step is to start to experiment with alternatives to realizing the feature to measure differences. Once you do that, the next step is to model the value intended to be provided by the feature and then track that during and after development. I recently published a short book where I describe this in more detail.
Jan, this “Using data to build better products” book is very valuable. It is short and easy to read. Are there similar books coming out in the future?
Thank you for your message! I’m writing on a book on platforms and ecosystems. Let me know if you want to proofread parts as they become available.